#
Architecture Overview
Warning
The contents in the children pages here were poorly filled in and will suffer heavy updates soon.
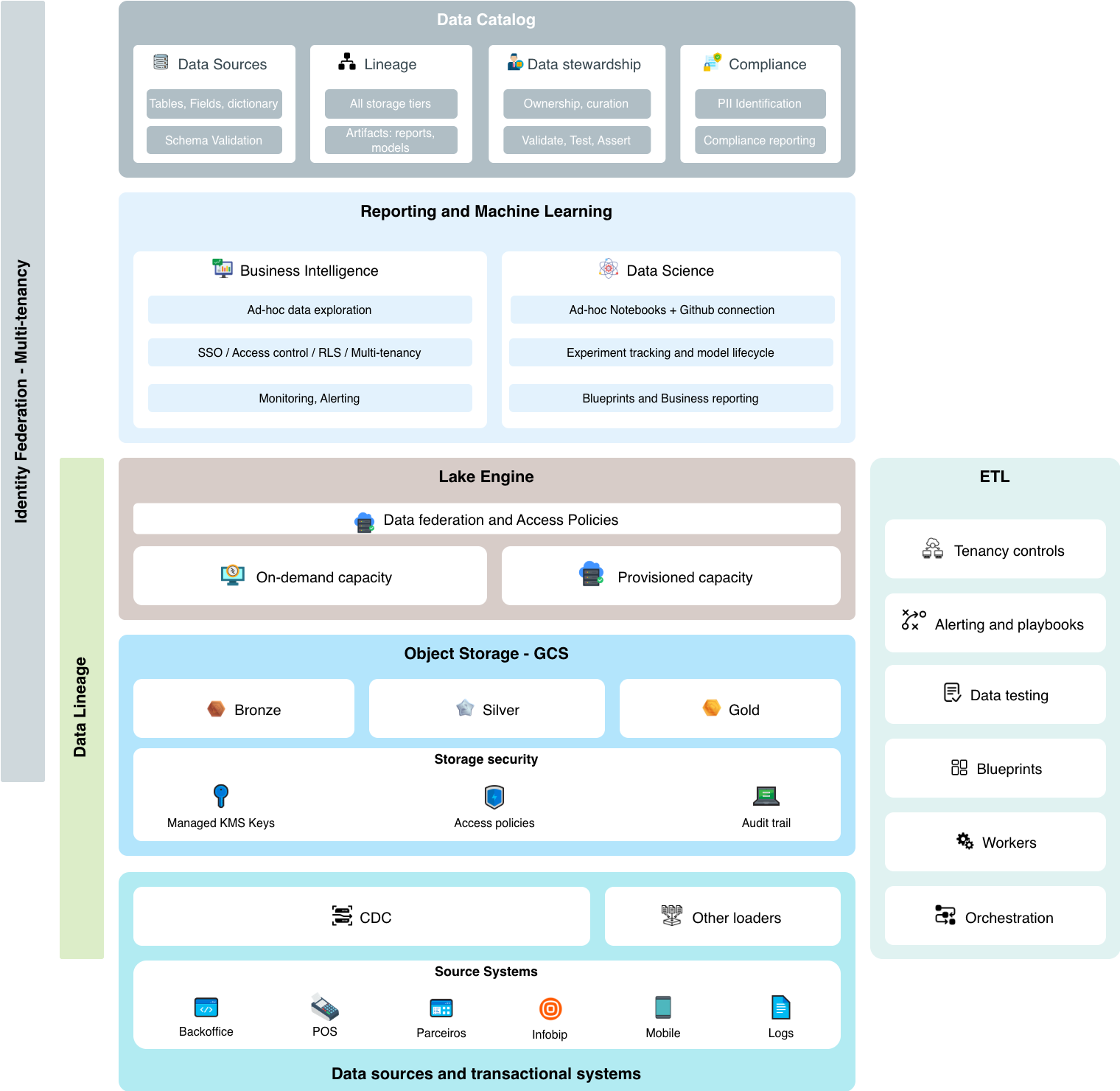
The UME data platform is designed to provide a unified, governed, and cost-effective environment for data ingestion, transformation, storage, and consumption. The architecture prioritizes data trust, governance, and operational efficiency.
#
Design Principles
- Governance First: Every layer incorporates access controls, lineage tracking, and audit capabilities.
- Trust in Data: Clear separation between raw, validated, and curated data through the medallion architecture.
- Cost Optimization: Thoughtful capacity planning with on-demand and provisioned options.
- Self-Service with Guardrails: Enable teams to explore and use data while preventing ungoverned sprawl.
#
Architecture Layers
The platform is organized into distinct layers, each with specific responsibilities:
#
Data Sources and Transactional Systems
The foundation layer captures data from various source systems including transactional databases, point-of-sale systems, partner integrations, mobile applications, and operational logs. Data flows into the platform through CDC (Change Data Capture) and specialized loaders.
#
Object Storage (GCS)
Google Cloud Storage serves as the persistent storage layer, organized using the medallion architecture:
- Bronze: Raw ingested data preserved as-is
- Silver: Cleaned, validated, and conformed data
- Gold: Business-ready, aggregated, and curated datasets
Storage security includes managed KMS keys, fine-grained access policies, and comprehensive audit trails.
Learn more about Object Storage
#
Lake Engine
The query and federation layer that enables unified access to data across different storage tiers and sources. It enforces access policies at query time and provides both on-demand and provisioned capacity options for cost optimization.
Learn more about the Lake Engine
#
ETL
The transformation layer handles data movement and processing with:
- Orchestration and scheduling
- Reusable blueprints for common patterns
- Data testing and validation
- Alerting and operational playbooks
- Multi-tenant controls
#
Data Catalog
The central governance hub providing:
- Data discovery and documentation
- Lineage tracking across all tiers
- Data stewardship and ownership
- Compliance monitoring and PII identification
Learn more about the Data Catalog
#
Reporting and Analytics
Business intelligence capabilities including ad-hoc exploration, governed dashboards, and KPI monitoring with proper access controls and multi-tenancy support.
#
Data Science
Machine learning platform capabilities including notebook environments, experiment tracking, model lifecycle management, and integration with version control.
#
Cross-Cutting Concerns
Several capabilities span across all layers:
- Identity Federation: Unified authentication and authorization across the platform
- Multi-Tenancy: Isolation and access controls for different business units and external tenants
- Data Lineage: End-to-end tracking from source systems to consumption
Learn more about Cross-Cutting Concerns