#
Executive summary
#
Introduction
Ume has grown very rapidly over the last few years and with its growth came challenges on how to govern and consume data.
In the current state, there is a large number of users with little control over how datasets are onboarded, transformed, maintained and governed. To be clear, there are good implementations here and there, but the organization lacks an unified "ways-of-working" view. Over the last months, this perspective started changing with the introduction of localized good practices driven by the data engineering team.
However, looking at the future, this initiative proposes a set of suggestions and a transformation plan to address current problems as well as prepare for future growth and scale. These suggestions will have to tackle both toolset and practices.
#
Toolset overview
Even though the company uses a set of tools that enable better controls than the currently applied, they are mostly loosely implemented, result of UME's rapid growth. In other cases, the tools don't enable for fine-grained access control policies, making it difficult to govern, share and consume data securely.
We will suggest changes sometimes on tools, sometimes just on practices to the architectural blocks that UME's personnel already use. But we will also introduce the best experience possible for data catalog and governance, making users feel confident and empowered to maintain data as their own.
So the plan is to craft together this new architecture vision, with a few tools to help achieve the best performance, governance experience possible.
But tools aren't everything.
#
Practices and methodologies
As part of the transformation plan, we introduce a set of methodologies and best practices that should be promoted across the company.
Blueprints for the diverse set of tasks performed across the data platform - such as data onboarding, transformations, dataset creations, dashboards configurations, etc - will be created, allowing for users to replicate those and even create new blueprints as new cases arise.
These blueprints will be governed and maintained in an accessible manner by the internal teams, and will be centrally available to all users to consult, use and contribute to. This can be enhanced with the use of agents to recommend best practices to ongoing implementations.
It is also envisioned that the rollout of this platform will bring controls such as reports that blend together usage, cost and best practices recommendations, in order to always have an eye on what is going on.
#
Transformation plan
The plan should be simple. With an architecture vision in mind and the direction chosen on a few set of tools and how to configure them, let's establish one or two PoCs to work on.
These PoCs should help us understand the interoperability between these tools, the user interaction, our procedures and if we're ticking all boxes we set out to achieve with the architecture vision.
#
Proposed Architecture Overview
We hereby propose an architecture view that is now born but should be a live organism that evolves as different requirements arrive. These next concepts wrap most of the logical blocks that a data architecture should have for analytical workloads. But we don't stop there.
It is known that we also have reverse-etl use cases and the good practices and tools shuold also embrace what happens in some transactional-focused workloads. e.g.: how we recommend schema evolution to happen across edge transactional systems so that we trace dependencies downstream?
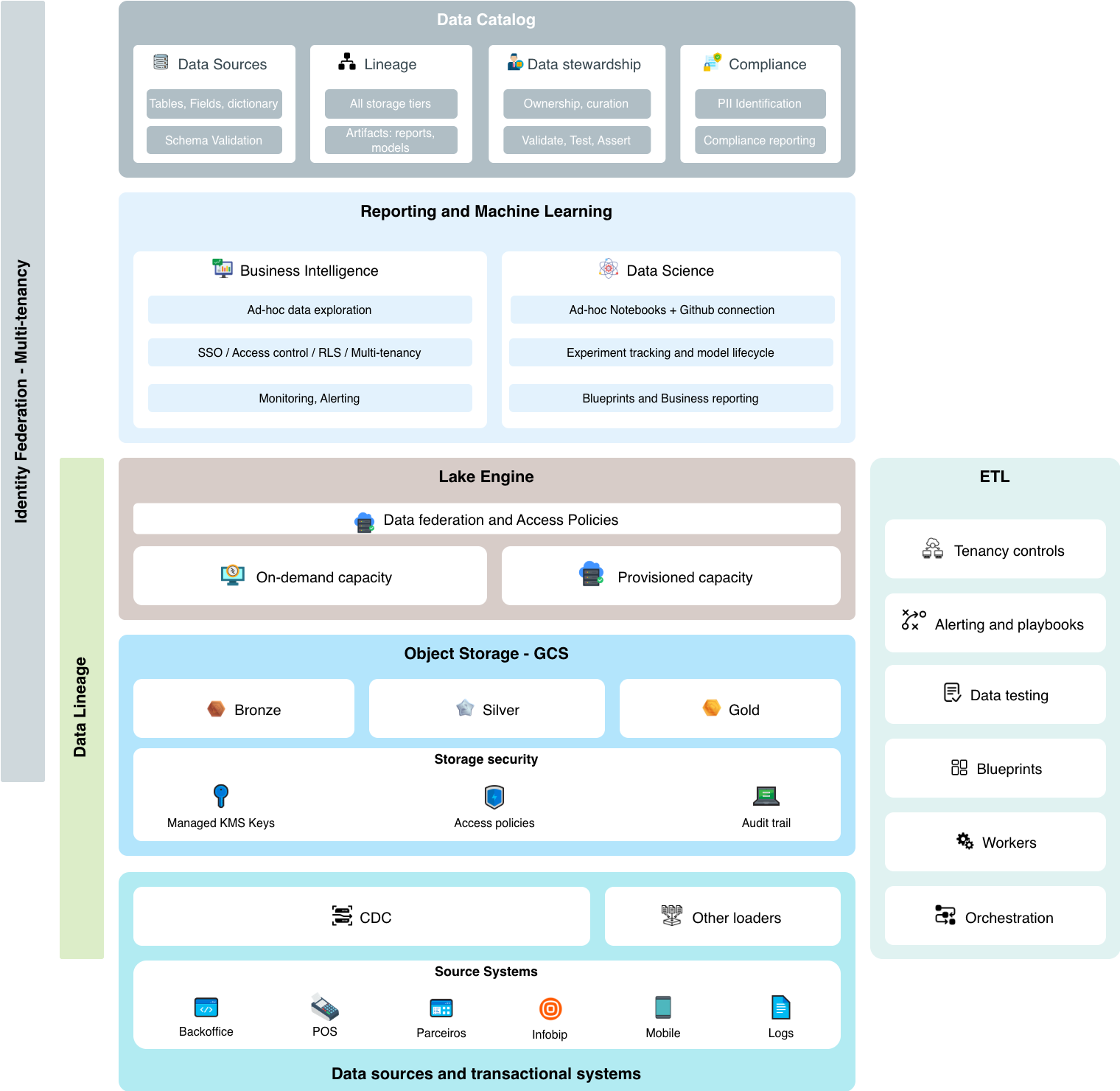
Below are short descriptions about each architectural block we consider and what tools we can bring in to solve our problems. More details about this in the Tools Selection section (to be structured based on Modules and Tools)
#
Object Storage
Landing zone for raw data. Decouples storage from compute. Enables fine-grained access policies, audit trails, and lifecycle management. Restricted access to data integration roles.
Tools: Google Cloud Storage (primary), AlloyDB/Cloud SQL (for structured landing)
#
Relational Database
Handles transactional workloads where latency matters and cost is predictable. Used when BigQuery's per-query model becomes prohibitive for high-frequency access patterns as well we for cases where interoperability with other relational databases can be leveraged as an advantage.
Tools: Google AlloyDB (primary), Postgres
#
Data Warehouse / Acceleration
OLAP workloads. Low maintenance (no indexes). Observability of partitioning and clustering for performance. Decoupled compute billing. Coupled with reporting that joins costs, performance and automated optimization suggestions.
Tools: BigQuery (primary), Clickhouse (experimental), BI Engine (acceleration layer), BigQuery Editions (+slots reservations/commitments) for great savings / BigQuery sharing (formaly BQ Analytics Hub) for added governance
#
ETL / Transformations
Governed pipelines with enforced schema verification for information reliability. Reusable blueprints accessible to business power users. Company-wide lineage visibility. Centralized test library.
Tools: dbt (primary), Dataform (BigQuery-native alternative)
#
Orchestration
Dependency-aware workflow management. CI/CD integration. YAML-based DAG definitions for simpler maintenance.
Tools: Cloud Composer / Airflow (primary)
#
Data Catalog & Governance
Central visibility of all data assets including downstream artifacts (dashboards, reverse-ETL). Maturity levels, stewardship, PII scanning, master data management. LLM-assisted discovery. User's home. Single source of thuth for metadata.
Tools: Datahub (primary), OpenMetadata (alternative)
#
Reporting / Dashboards
Single tool for most if not all visualization needs. Centralized KPI monitoring with anomaly detection. Row-level security. Identity federation for audit trails.
Tools: Looker Studio (primary), Metabase Cloud (reduced effort for artifact migration), Hex (exploration + ML)
#
Data Science
Opinionated devkit with remote execution capabilities. GitHub as source of truth. Blueprints for full model lifecycle: conception, development, serving, observability, retraining, sunsetting. Feature store patterns. Lineage and audit exposure.
Tools: Vertex AI, Hex (notebooks + viz)
#
Transition Plan
Land and expand.
The first objective is to listen and understand aspects like tools, pain points and processes. Then with a little bit of discussion, everyone of the stakeholders agree on a few set of problems to tackle first and what tools we can test in this first immediate cycle.
So at a certain point when documenting and discovering is enough, we start the first implementation cycle where we will have established the first one or two problems to address, and for each of them we will implement a vertical subset of the architectural view described above that delivers a visible value to builders and to the business.
During and after this implementation we will have learned more about the tools, processes and developer/user experience so that we update our view and plan for the next steps.
The currently defiend projects we're going to start working on are:
- FinOps - Challenges on processes - there's much to enhance in terms of reliability, repeatability and auditability - and on data reliability - e.g.: Retrieval of installment values.
- Atendimento - There is a diverse set of data coming from different systems and partners, with great room for optimization and unification into a centralized, performant set of reports and self-service analyses.
#
Conquering the sea of data
If we only look at analytical workloads, there is a vast sea of datasets living in many places, transformations running in different workloads and languages managed by different repositories, dashboards developed across different tools and so much more complexity.
The goal with giving the organization an unified data catalog is to have this massive glass pannel through which users - business and technical - will able to observe all data that exists on UME's GCP, to know what transformations do with this data and what reports exist across the organization.
With that, each dataset, etl process, dashboard will be assigned a stweard person, a quality score - result of automated testing - a freshness information and other marks that will attest the validity of that information.
So during the first implementations, these migrated datasets, that are compliant with the new way of doing, will receive a badge. Older datasets or legacy datasets can be moved into deprecation areas and be slowly brought back into compliance.
The wish is that there will be so much pulse and so much going on in terms of feedback, that users should feel compelled to bring data into quality controls.
To achieve this, the implementation efforts should put developer experience at the central stage.