#
Architecture and tools
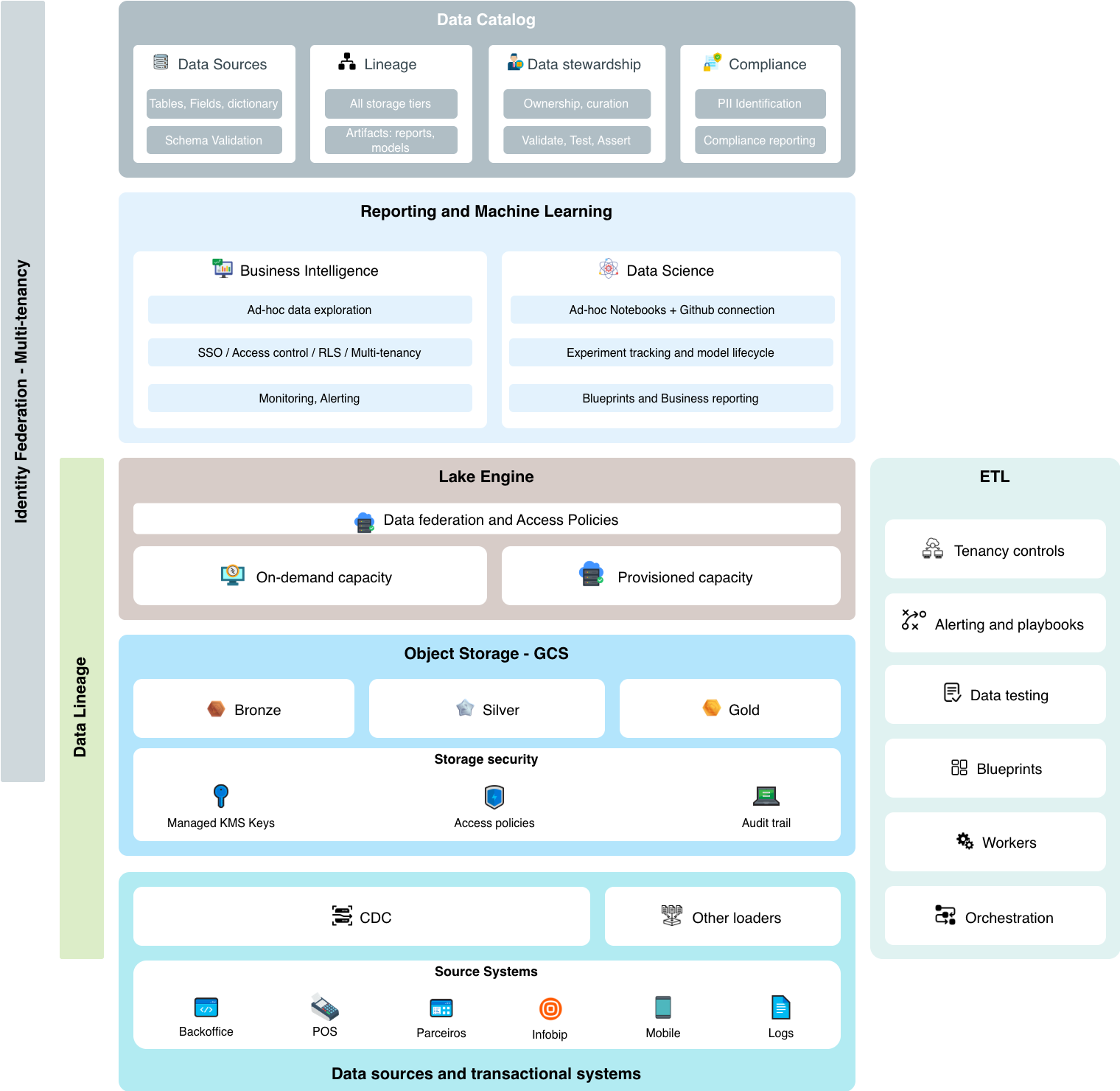
As presented in the Executive Summary, we hereby present a logical architecture view, and the intention behind this logical separation is to help us address blocks of competence, attention points and actions that will bring us to a good and governed utilization of reports.
For example, for onboarding new data asset, data engineers should know what is expected and what are the common practices across the company. Infrastructure operators should be at peace to know that data extracts are being performed according to standards and if not, alerts will pop-up.
Similarly, when maintaining on data transformations, engineers shuold know implementation patterns and understand the impacts of their changes.
And beyond all, separating the logical blocks of infrastructure help us understand what interoperability mechanisms we expect from each of them when building a governance platform. For instance, As a data steward for a business KPI, I would like to know the lineage and freshness from the data source through all transformations to all reports that use my information. This allows us to formulate a few questions:
- How to trace lineage from source to all transformations?
- How to extend lineage to add not only transformation built lineage but also include rammifications that happen within the reporting tools?
- How to enforce schema validation in the earliest stages and what actions should be taken when schema validation fails?
Answering these questions help us decide two things at least: tools and processes. The contents of this section Architecture and Tools takes a shot at answering those, suggesting tools and practices that when put together should offer a good experience and achieve the expected business results.
#
Design Principles
- Governance First: Every layer incorporates access controls, lineage tracking, audit and monitoring capabilities. Operators should as much as possible be able to expose what goes on on each block so that a big 360 picture can be seen from a governance layer.
- Reduced operation needs: Find the best ballance between the desired experience and the lowest possible infrastructure overhead. We rather focus on implementing business logic than spending our time on technical aspects such as infrastructure.
- Reproducibility: ETL Code, dashboard logic or any other artifact built on top of this view should enable for externally represented code. This means being able to track changes and making it easier to recover from disasters when we introduce automation processes.
- Trust in Data: Clear separation between raw, validated, and curated data through the medallion architecture. Have this mirrored on the data catalog so that automated and manual processes can catch deviations.
- Cost Optimization: Thoughtful capacity planning with on-demand and provisioned options.
- Self-Service with Guardrails: Enable teams to explore and use data while preventing ungoverned sprawl. Offer operational monitoring tools that oversee block such as storge, DW, processing, IAM and alert when anomalies happen.
- Single point of metadata maintenance: We elect a single point of metadata maintenance reduce maintenance overhead. Have jobs or event-based processes to discover data and metadata from different storage SKUs. Maintain descriptions and documentation in a single point - Data Catalog tool. Push metadata back to sources - e.g.: data catalog to BigQuery.
- Right identity - Reduce the usage of long-lived credentials, leverage workload identity when necessary and whenever possible use identity federation to propagate user and workload identities.